キャッシュアーキテクチャ¶
導入¶
Apache Traffic Server™ は HTTP プロキシーであると同時に HTTP キャッシュでもあります。 Traffic Server はどんなオクテットストリームもキャッシュできますが、現状サポートしているのは HTTP プロトコルで配信されたオクテットストリームのみです。そういがストリームが (HTTP プロトコルヘッダーと共に) キャッシュされたとき、それはキャッシュ内の オブジェクト と呼ばれます。それぞれのオブジェクトは キャッシュキー と呼ばれるグローバルにユニークな値によって識別されます。
The purpose of this document is to describe the basic structure and implementation details of the Traffic Server cache. Configuration of the cache will be discussed only to the extent needed to understand the internal mechanisms. This document will be useful primarily to Traffic Server developers working on the Traffic Server codebase or plugins for Traffic Server. It is assumed the reader is already familiar with the Administrator's Guide and specifically with HTTP プロキシーキャッシュ and Proxy Cache Configuration along with the associated configuration files.
不幸なことに、内部用語は一貫していません。そのためこのドキュメントにおいては一貫性を得るためにコード内で使われるものとは違った方法で頻繁に用語を使用します。
キャッシュレイアウト¶
次節では永続的キャッシュデータがどのような構造を持つかを説明します。 Traffic Server は永続的ストレージを区別されてないバイト列の集合として扱い、それ以外の構造を仮定しません。特に、ホストオペレーティングシステムのファイルシステムは使用しません。ファイルが使われるとすればそれは使用される一組のバイト列を区切るために使われます。
キャッシュストレージ¶
Traffic Server キャッシュ用の生のストレージは storage.config で設定されます。ファイルの各行は キャッシュスパン を定義し、それが一律の永続ストアとして扱われます。
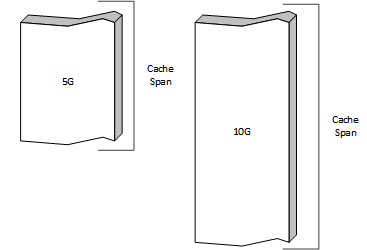
二つのキャッシュスパン
このストレージは一組の キャッシュボリューム で構成されます。 キャッシュボリューム は volume.config で定義されます。これらは全ての他の管理レベルの設定に使われる単位となります。
キャッシュボリュームは全体のストレージのパーセンテージかあるいはストレージの絶対的な量で定義できます。デフォルトでは、それぞれのキャッシュボリュームは堅牢性のため全てのキャッシュスパンに散在されます。キャッシュボリュームとキャッシュスパンの共通部分が キャッシュストライプ です。それぞれのキャッシュスパンは複数のキャッシュストライプに分割されますし、それぞれのキャッシュボリュームはこれらのストライプの集合です。
もし、例としてキャッシュスパンのキャッシュボリュームが以下のように定義されていたら

実際のレイアウトはこのようになるでしょう。
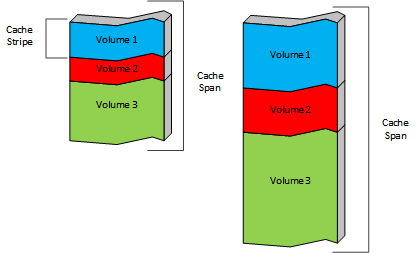
キャッシュストライプはキャッシュを実装するための基本的な単位です。キャッシュされたオブジェクトは全体が単一のストライプひいては単一のキャッシュスパンに保存されます。オブジェクトが複数のキャッシュスパンやボリュームに分割されることは決してありません。オブジェクトは オリジンサーバー からオブジェクトを取得するために使われた URI。 のハッシュに基いて自動的にストライプに割り当てられ (そして同様にキャッシュボリュームにも割り当てられ) ます。これは hosting.config である程度までは制御することが出来、特定のホストやドメインからのコンテンツを特定のキャッシュボリュームに保存することをサポートしています。バージョン 4.0.1 以降では特定のキャッシュボリュームの中のどのキャッシュスパン (そしてその結果どのキャッシュストライプ) にするかも制御することができます。
キャッシュスパン、キャッシュボリューム、そしてそれらを構成するキャッシュストライプのレイアウトと構造は、全て storage.config と:file:cache.config から取得され、 :process:`traffic_server` が開始された時にはじめから再計算されます。従って、これらのファイルへの任意の変更は(ほとんど常に)それら全ての既存のキャッシュを無効化します。
ストライプ構造¶
TS| は、キャッシュストライプと結び付けられたストレージを区別されないバイト列のスパンとして扱います。内部的に各ストライプはほぼ完全に独立して扱われます。この節で記述されるデータ構造は、各ストライプに複製されます。内部的に ボリューム という単語はこれらのストライプに使用され、主に Vol で実装されています。ユーザが思うボリューム (このドキュメントでは キャッシュボリューム ) は、 CacheVol で表現されます。
注釈
ディレクトリはストライプに配置されるため、ストライプ割当はオブジェクトを扱うような動作をする前に行われなければなりません。ストライプ割当が変更されたキャッシュオブジェクトは、新しいストライプ上で発見されないであろうディレクトリデータとして事実上消失します。
キャッシュディレクトリ¶
コンテンツはディレクトリを使って追跡されます。ディレクトリの各要素は ディレクトリエントリ と呼ばれ Dir で表されます。各エントリはキャッシュ内の連続したストレージのチャンクを参照します。これらは フラグメント 、 セグメント 、 docs 、 ドキュメント 、その他いくつかのものとしてさまざまな呼ばれ方をします。コード内で最もよく参照されているのでこのドキュメントでは フラグメント という用語を使います。(Doc に対応する) Doc はフラグメントへのヘッダーデータに言及するときに使用します。概してディレクトリは キャッシュ ID をキーとしたハッシュとして扱われます。キャッシュ ID がディレクトリエントリを発見するためにどのように使われるかについては ディレクトリ検索 を参照してください。次にキャッシュ ID は キャッシュキー から計算されます。 キャッシュキー はデフォルトではコンテンツの URL です。
ディレクトリはメモリに常駐する構成で使用されるので、ディレクトリエントリは可能な限り小さくなっています。(現在は 10 バイト)このことは、そこに保存できるデータに幾つかの制約を強要します。一方でほとんどのキャッシュミスはディスク I/O を要求せず、大きな性能面の恩恵を得ることになります。
ディレクトリは常に最大のサイズになります。ストライプが一旦初期化されると、ディレクトリサイズは固定されて二度と変更されません。このサイズは、ストライプのサイズに(大雑把に、線形に)関係します。この理由により Traffic Server のメモリ使用量は、ディスクキャッシュのサイズに強く依存します。ディレクトリサイズは変わらずメモリ要件もまた変わらないため、 Traffic Server がキャッシュに保存されたコンテンツが増えてもメモリ消費量が増えることはありません。キャッシュが空の状態で Traffic Server を動作させるのに十分なメモリがあるなら、キャッシュが満ちた状態で動作するのに十分です。
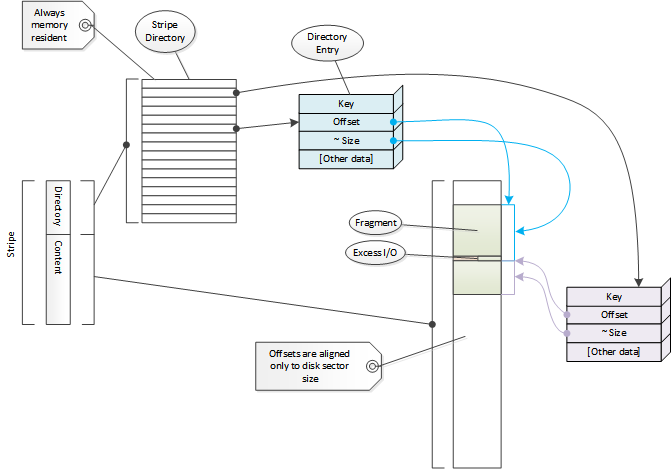
それぞれのエントリはストライプ内でのオフセットとサイズを保存します。ディレクトリエントリに保存されるサイズは おおよそのサイズ でありフラグメント内の実際のデータと最低でも同じになります。正確なサイズデータはディスク上のフラグメントヘッダーに保存されます。
注釈
HTTP ヘッダー内のデータはディスク I/O 無しに調べることは出来ません。これにはオブジェクトの元の URL を含みます。キャッシュキーは明示的には保存されていないので、その結果確実に取得することは出来ません。
ディレクトリは衝突解決に チェイン法 を使うハッシュテーブルです。各エントリは小さいのでハッシュバケットのリストヘッダーとして直接使用されます。
チェイン法はグループ化する構造をディレクトリ内のエントリに課すことで実装されています。第一レベルのグルーピングは ディレクトリバケット です。これは固定の数 (現在は 4 、DIR_DEPTH で定義されています)のエントリです。これはそれぞれのキャッシュバケット内に最初のエントリを持つ基本的なハッシュバケットを定義するのに役立ちます。キャッシュバケットはハッシュバケットのルートの役目を果たします。
注釈
バケット という用語はハッシングのための概念的なバケットとディレクトリ内の構造をグループ化するメカニズムの両方を意味するコードで使われています。これらを区別する必要に応じてこれらは修飾されます。修飾無しの バケット という用語はほぼ常にディレクトリ内の構造をグループ化することを意味するのに使われます。
ディレクトリバケットは セグメント の中にグループ化されます。ストライプの中の全てのセグメントは同じ数のバケットを持ちます。ストライプ内のセグメントの数は 1 つのセグメント内のエントリの数が 65,535 (216-1 を超えない範囲で各セグメントがなるべく多くのバケットを持つように選ばれます。
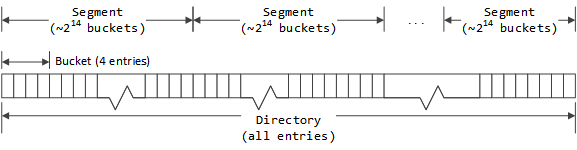
各ディレクトリエントリは前と次のインデックス値を持ちそれは同一セグメント内のエントリを結びつけるために使われます。 65,535 エントリより多くを持つセグメントは存在しないので、インデックス値を保存するには 16 ビットあれば十分です。ストライプヘッダーはエントリインデックスの配列を格納し、エントリインデックスはエントリのフリーリストのルートとして使われます。ルートそれぞれのセグメントに 1 つ存在します。アクティブなエントリはバケット構造を使って保存されます。ストライプが初期化されるとき、それぞれのバケットの最初のエントリはゼロクリア (未使用とマーク) され、他のエントリはストライプヘッダー内の対応するセグメントのフリーリストに置かれます。これはそれぞれの ディレクトリバケット の最初のエントリはハッシュバケットのルートとして使われ、そのためフリーリスト内に置かれるよりは未使用としてマークされることを意味します。ディレクトリバケット内の他のエントリは対応するハッシュバケットに追加されることが望ましいですが、必須ではありません。セグメントのフリーリストは予備のバケットエントリが順番に追加されるように初期化され、全ての第 2 ディレクトリバケット、第 3 ディレクトリバケット、そして第 4 ディレクトリバケットが続きます。フリーリストは FIFO なので、これは予備のエントリはまず全ての第 4 ディレクトリバケットから選択され、次に第 3 ディレクトリバケットから選択され、などとなることを意味します。バケット内に新しいディレクトリエントリを割り当てるときはエントリは先頭から最後に検索され、バケットの局所性 (つまり、同じハッシュバケットにマッピングする キャッシュ ID は同じディレクトリバケットを使う傾向が強くなるように) を最大化します。
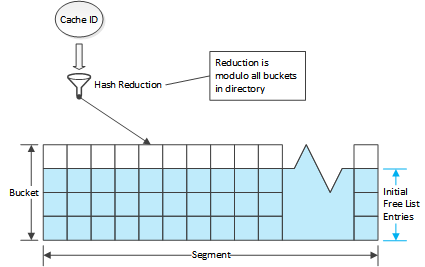
Entries are removed from the free list when used and returned when no longer in use. When a fragment needs to be put in to the directory the cache ID is used to locate a hash bucket (which also determines the segment and directory bucket). If the first entry in the directory bucket is marked unused, it is used. Otherwise, the other entries in the bucket are searched and if any are on the free list, that entry is used. If none are available then the first entry on the segment free list is used. This entry is attached to the hash bucket via the same next and previous indices used for the free list so that it can be found when doing a lookup of a cache ID.
ストレージレイアウト¶
ストレージレイアウトは、ストライプメタデータの後ろにキャッシュされたコンテンツが続きます。メタデータは三つの要素、ストライプヘッダ、ディレクトリ、ストライプフッタで構成されます。メタデータは二度保存されます。ヘッダとフッタは VolHeaderFooter のインスタンスです。これは可変長配列を末尾に持つことができるスタブ構造体です。この配列はディレクトリのルートのセグメントフリーリストとして使用されます。各要素はセグメントのフリーリストの、最初の要素のセグメントインデックスを持ちます。フッタは、セグメントフリーリストを伴わないヘッダのコピーです。ヘッダのサイズはディレクトリに依存しますが、フッタは依存しません。
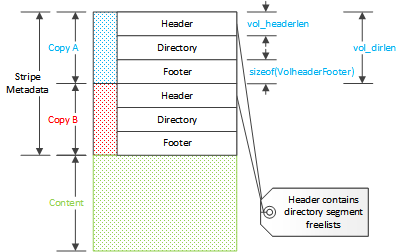
各ストライプは、基本的なレイアウトを表現する幾つかの値を持ちます。
- skip
- ストライプデータの開始地点です。これはホストオペレーティングシステムによる問題を回避するために物理デバイスの始点に予約されたスペース、もしくは他のストライプにキャッシュスパンのスペースが使用されていることを表すオフセットのどちらかを表します。
- start
- ストライプメタデータの後からの、コンテンツの開始地点を示すオフセット
- length
- ストライプのバイトの合計値。
Vol::len - data length
- コンテンツストレージとして使用可能なストライプのブロックの合計値。
Vol::data_blocks
注釈
キャッシュコードの size や length を扱う場合、特に注意しなければなりません。これらは様々な箇所で、少なくとも三つの違うメトリクス(バイト、キャッシュブロック、ストアブロック)が使われているからです。
ディレクトリの合計サイズ (エントリ 数) は、 キャッシュストライプ のサイズを取得して平均オブジェクトサイズで割ることで計算されます。ディレクトリは常にメモリ量を消費し、それはもしキャッシュサイズが増加するなら Traffic Server のメモリ要件も増加するという効果を引き起こします。平均オブジェクトサイズはデフォルトでは 8000 バイトですが、 proxy.config.cache.min_average_object_size で設定できます。平均オブジェクトサイズを増加させることにより、キャッシュに保存するオブジェクト数を減らすことと引き換えに、ディレクトリのメモリ使用量を減らすことができます。
コンテンツエリアは実際のオブジェクトを保存し、最もキャッシュされてから時間が経過したオブジェクトを新たなドキュメントで上書きする循環バッファとして使用されます。ストライプの新たなキャッシュデータの位置は、 書込みカーソル と呼ばれます。これはデータが書込みカーソルによって上書きされる場合、たとえ失効していなくても、オブジェクトは事実上キャッシュから立ち退かせられることを意味します。もしオブジェクトが上書きされる場合、検出されずディレクトリは更新されません。代わりに、もしオブジェクトが将来アクセスされてフラグメントのディスク読込みが失敗する場合、警告されます。
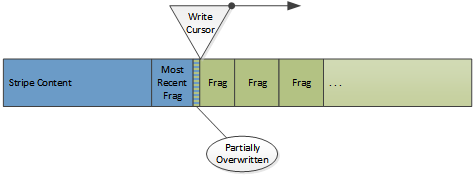
書込みカーソルとキャッシュ内のドキュメント
注釈
ディスク上のキャッシュデータは永遠に更新されません。
これは、心に留めておくべき重要な事です。更新されるように見えるもの ( 新鮮ではない コンテンツをリフレッシュし、 304 を返すような) は、実際には書込みカーソルで書き込まれているデータの新しいコピーです。オリジナルは書込みカーソルがディスクのその位置に到着する時に消去される、 "死んだ" スペースとして残されます。一旦ストライプディレクトリが (メモリ内で) 更新されると、キャッシュ上のオリジナルのフラグメントは事実上破棄されます。これは他のケースでも同様に用いられる、一般的なスペース管理技術です。もしオブジェクトをキャッシュから削除する必要がある場合、ディレクトリだけ変更する必要があります。他の動作行う必要はありません (特にディスク I/O は必要ありません)。
オブジェクトの構造¶
オブジェクトは二つのデータのタイプ、メタデータとコンテンツデータとして保存されます。メタデータは、 HTTP ヘッダを含むオブジェクトとコンテンツに関する全てのデータです。コンテンツデータはオブジェクトのコンテンツで、オブジェクトとしてクライアントに配信されるオクテットストリームです。
オブジェクトは、キャッシュに格納される Doc 構造体をルートとします。Doc は キャッシュフラグメント のヘッダデータとして提供し、各フラグメントの先頭に置かれます。オブジェクトの最初のフラグメントは 先頭の Doc と呼ばれ、常にオブジェクトメタデータを含んでいます。オブジェクトの任意の操作は、最初にこのフラグメントを読み込みます。そのフラグメントはオブジェクトの キャッシュキー を キャッシュ ID に変換することにより発見され、その後そのキーを使って ディレクトリエントリ が検索されます。ディレクトリエントリは、その時ディスクから読み込まれる先頭のフラグメントのオフセットとおおよそのサイズを持ちます。このフラグメントは、全てのオブジェクトのプロパティ (コンテンツ長のような) に加えて、リクエストヘッダとレスポンスを持ちます。
Traffic Server はオブジェクト用に コンテンツ変換 をサポートします。これらを 代替 と呼びます。全ての代替の全メタデータは、代替のセットとそれらの HTTP ヘッダを含む先頭のフラグメントに格納されます。これは、 先頭の Doc がディスクから読込まれた後に、 代替セクション が実行されることを有効にします。複数の代替を持つオブジェクトは、先頭のフラグメントとは別に保存された代替コンテンツを持ちます。一つの代替のみ持つオブジェクトは、コンテンツはメタデータと同じ (先頭の) フラグメントに置かれるかもしれないし、そうでもないかもしれません。個々の分離された代替コンテンツはディレクトリエントリを割り当てられ、エントリのキーは先頭のフラグメントのメタデータに保存されます。
バージョン 4.0.1 以前は、ヘッダデータはディスクイメージの可変長領域に整列される CacheHTTPInfoVector クラス内に保存され、オブジェクトを保存する必要がある場合、追加フラグメント情報がその後ろに続きます。
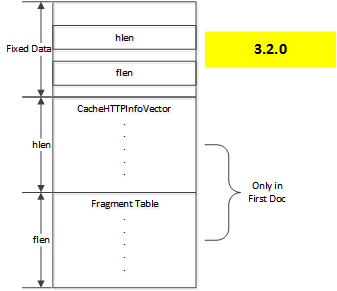
3.2.0 の Doc レイアウト
この方法では、一つのフラグメントテーブルのみでは複数の 代替[#multiple-alternates]_ を持つオブジェクトに対しては信頼性を確保できない問題がありました。したがって、フラグメントデータはメタデータ用に分離された可変長領域から CacheHTTPInfoVector へ直接統合されるよう移動し、以下の形式のレイアウトに生まれ変わりました。
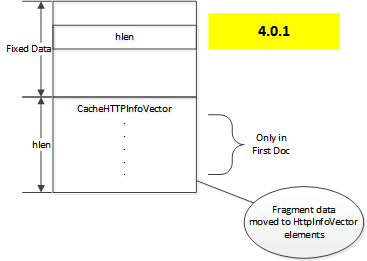
4.0.1 の Doc レイアウト
ベクターの各要素は、各代替に加えて (もしあれば) HTTP ヘッダとフラグメントテーブル、 キャッシュキー を含みます。このキャッシュキーは 最古の Doc として参照される ディレクトリエントリ を特定します。これは代替のコンテンツの開始位置です。
オブジェクトが最初にキャッシュされる際、それは単一の代替を持ち、 (大きすぎない場合は) 先頭の Doc に格納されます。これはコード中で 常駐代替 と呼ばれます。この処理はオブジェクトの最初の保存時にのみ発生し得ます。メタデータが更新される場合 (If-Modified-Since リクエストに対し、 304 を返すなど) 、オブジェクトが小さくなければ、オブジェクトデータはオリジナルのフラグメントに取り残され、新しいフラグメントが先頭のフラグメントとして書き込まれ、非常駐の代替を作成します。 proxy.config.cache.alt_rewrite_max_size より小さい長さを、 小さい と定義します。
注釈
CacheHTTPInfoVector は first Doc にのみ保存されます。earliest Doc を含む、 first Doc に続くオブジェクトの Doc インスタンスはゼロの hlen を持つはずであり、もしそうでないものは無視されます。
巨大なオブジェクトは、キャッシュに書き込まれる時に複数のフラグメントに分割されます。これは、ドキュメント長の合計が first Doc もしくは earliest Doc のコンテンツより長いことを示します。このような場合には、フラグメントオフセットテーブルが保存されます。このテーブルは(オフセットが常にゼロであるような)先頭のフラグメントの次以降の各フラグメントのコンテンツデータの先頭バイトを指し示す、オブジェクトコンテンツ全体の中でのバイトオフセットを含みます。これは範囲内のデータを含まない、中間にあるフラグメントをスキップ可能にすることで、巨大なオブジェクトを非常に効率的に提供するためのレンジリクエストを可能にします。シーケンスの最後のフラグメントは、明示的なエンドマーク無しにフラグメントサイズとオフセットがオブジェクトの合計サイズの最後に到達することにより検出されます。各フラグメントは、計算的に前のものと繋がっています。フラグメント N のキャッシュキーは、以下により計算されます:
key_for_N_plus_one = next_key(key_for_N);
ここで next_key は既存のキャッシュキーから新しいキャッシュキーを決定論的に計算するグローバル関数です。
複数のフラグメントを伴うオブジェクトは、 (最古の Doc を含む) データフラグメントが先頭に書き込まれ、 先頭の Doc が末尾に書き込まれる形でレイアウトされます。ディスクから読み込まれる時、先頭と最古の Doc の両方は、ドキュメント全部がディスクに存在することを確認するため検証されます。 (それらが書込みカーソルにより上書きされていないことを確認することで試験されます) (これらの Doc は他のフラグメントのブックエンドとなります。書込みカーソルは、検証された Doc インスタンスの少なくとも一つの上書き無しに、ドキュメントを上書き出来ません) 単一のオブジェクトのフラグメントは、 Traffic Server に届いたデータとして異なるオブジェクトのデータが挟み込められてしまうため、必ずしも隣接しないように並べられていることに注意してください。
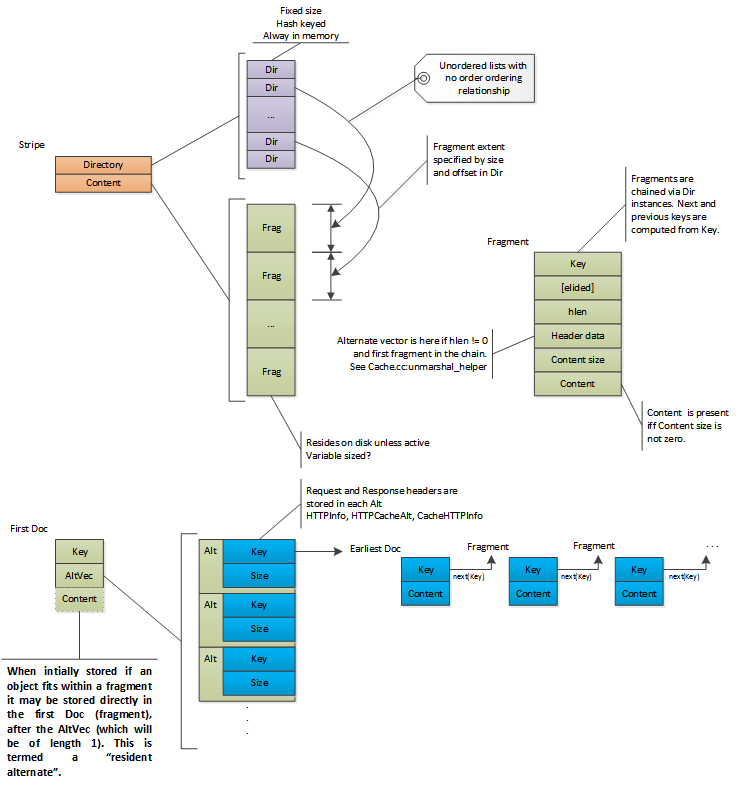
オブジェクトストレージの、複数の代替と複数のフラグメント
キャッシュへピン留めされたドキュメントは上書きされてはならず、そのためそれらは書込みカーソルの前に退避させられます。各フラグメントは読み込まれ、再書込みされます。潜在的に信頼性の低いディスク領域ではなくメモリ上で検出できるよう、退避されるオブジェクトの特殊な検出メカニズムが存在します。データを退避させることができない書込みカーソル直前のデットゾーンがあるため、ピン留めされたオブジェクトを発見するためにキャッシュは書込みカーソルより先にスキャンします。退避されたデータはディスクから読み込まれて書込みキューに置かれ、出番が来ると書き込まれます。
オブジェクトは cache.config ファイルと、 proxy.config.cache.permit.pinning にゼロでない値 (デフォルトではゼロ) を設定した場合のみピン留めできます。書込みカーソルが接近している際に使用中のオブジェクトは、基本的な退避メカニズムを同様に使用しますが、 Dir の明示的な ピン留め 無しに自動的に扱われます。
| [1] | それは、ある状況下では代替が正確になりません。 |
追加情報¶
データ構造のいくつかの概説。
循環バッファ¶
キャッシュは 循環キャッシュ であるため、キャッシュオブジェクトは無期限の保存はされません。たとえオブジェクトが 新鮮でない わけではなくても、ボリュームのキャッシュサイクルとして上書きする可能性があります。 ピン留め してオブジェクトをマーキングすることにより書込みカーソルの通過をやり過ごしてオブジェクトを保護することができますが、これは書込みカーソルを跨いでオブジェクトをコピーすること、実際にはキャッシュ内に再保存を行うことによって処理されます。巨大なオブジェクトや大量のオブジェクトのピン留めは、過度のディスク動作を引き起こす場合があります。ピン留めの元々の目的は、管理者によって明示的にマークされた小さく頻繁に使用されるオブジェクトのためのものでした。
循環バッファの目的は、単純にオブジェクトの失効データがクライアントに提供されるのを防ぐことです。失効データは一般的な意味での削除やクリーンアップはされません。書込み処理は書込みカーソルでのみ発生するので、どんなイベントにおいてもスペースは直ちには取り戻せません。オブジェクトの削除は (最終的には) スペースを解放してかつドキュメントをアクセス不可能にするのに十分な処理である、ボリュームディレクトリのディレクトリエントリの削除のみで成り立ちます。
ウェブコンテンツは比較的小さく特に一貫もしていなかったので、歴史的にキャッシュはこの方法の通りに設計されています。この設計は高性能でかつ低い一貫性の要件となります。ストレージのフラグメンテーション問題は発生せず、またキャッシュミスやオブジェクトの削除がディスク I/O を要求することもありません。巨大なオブジェクトの長期間保存は特別うまくは扱いません。この部分の動作の詳細については ボリュームタグ付け の付録を見てください。
ディスク障害¶
キャッシュはディスク障害に比較的強いように設計されます。各 キャッシュボリューム の各 ストレージユニット はほぼ独立しているので、ディスクの損失は対応する Vol インスタンス (ストレージユニットを使うキャッシュボリュームにつき 1 つ) が使えなくなることを単に意味します。主な課題は故障したディスクから運用中のボリュームへの割当の配布中に、まだ運用中のボリューム上のオブジェクトの割当を両方保存するためのボリューム割当テーブルの更新処理です。これはほとんどが以下の中で処理されます:
AIO_Callback_handler::handle_disk_failure
ディスクを稼働状態に戻すのは非常に困難な作業です。 キャッシュキー のボリューム割当の変更は、全ての現在キャッシュされているデータへのアクセスを不可能にします。ディスクが故障した際にこれは当然ながら問題にはなりませんが、新しいストレージユニットが動作中のシステムに追加された場合、どのキャッシュされたオブジェクトが事実上追い出されるか決定するのが少々扱いにくい処理です。このためのメカニズムは何かないか、まだ調査中です。
実装の詳細¶
ストライプディレクトリ¶
メモリ上のボリュームディレクトリエントリは、以下の通りに定義されます。
-
class
Dir¶ P_CacheDir.hで定義される。名前 型 用途 offset unsigned int:24 (ボリュームに関連した)メタデータの先頭バイトのオフセット big unsigned in:2 サイズの乗数 size unsigned int:6 サイズ tag unsigned int:12 (高速な衝突チェックの為の)キーの一部 phase unsigned int:1 Phase of the Doc(for dir valid check)head unsigned int:1 オブジェクトの先頭のフラグメントを示すフラグ pinned unsigned int:1 ドキュメントがピン留めされていることを示すフラグ token unsigned int:1 不明なフラグ next unsigned int:16 次エントリへのセグメントローカルインデックス offset_high inku16 上位オフセットビット
ストライプディレクトリは Dir インスタンスの配列です。各エントリはキャッシュされたオブジェクトを持つボリュームのスパンを参照します。キャッシュ内の各オブジェクトは少なくとも一つのディレクトリエントリを持つため、このデータは可能な限り小さくなるよう設計されました。
オフセット値はボリューム内におけるオブジェクトの開始バイトです。それは offset (下位 24 ビット) と offset_high (上位 16 ビット) メンバに渡って分割された 40 ビット長です。キャッシュボリュームの各ストレージユニット毎にディレクトリは存在するため、この値はボリュームに接続されたストレージユニットの一部分へのオフセットであることに注意してください。
size と big 値はオブジェクトを持つスパンの大まかなサイズを計算する為に使用されます。この値はストレージのオフセット値から読込み処理を行うためのバイト数として使用されます。正確なサイズは:cpp:class:Doc のオブジェクトメタデータに含まれており、一旦読込みが完了した後に参照されます。この理由により、おおよそのサイズは少なくとも実サイズと同じである必要がありますが、外部からのバイト列の読み込みというコストを費やして読み込んだ結果、より大きくなることがあります。
フラグメントの大まかなサイズの計算は以下のように定義されます。:
( *size* + 1 ) * 2 ^ ( CACHE_BLOCK_SHIFT + 3 * *big* )
ここで CACHE_BLOCK_SHIFT は基本的なキャッシュブロックのサイズのビット幅(9 であり、 512 のセクタサイズに対応している) です。したがって現在の定義にその値を使った値は以下のようになります。:
( *size* + 1 ) * 2 ^ (9 + 3 * *big*)
big は 2 ビットであるため、size の乗数の値は、
big 乗数 最大サイズ 0 512 (2^9) 32768 (2^15) 1 4096 (2^12) 262144 (2^18) 2 32768 (2^15) 2097152 (2^21) 3 262144 (2^18) 16777216 (2^24)
size は実際上は 1 だけずれており、そのため 0 が乗数の単一のユニットを示すことに注意してください (訳注: size は 0 から始まりますが、 0 が単一のユニット、 1 が 2 つのユニットを示します)。
ターゲットフラグメントサイズは records.config の値 proxy.config.cache.target_fragment_size で設定できます。
この値は キャッシュエントリ乗数 の倍数になるように選択するべきです。 2 の冪乗にする必要はありません。 [] より大きなフラグメントは I/O の効率を向上しますが、無駄なスペースが増加します。デフォルトサイズ(1M, 2^20)はほとんどの環境において合理的な選択です。ただし、非常に特殊なケースではこのパラメータをチューニングすることにより恩恵が得られる場合があります。 Traffic Server は Doc 構造のサイズより少ない 4M(2^22) である 4,194,232 バイトの内部的な最大値を強制します。事実上、最大の合理的なターゲットフラグメントサイズは 4M - 262,144 = 3,932,160 です。
フラグメントがディスクへ保存される際、キャッシュインデックスエントリのサイズデータはフラグメントのサイズにより許容される最小粒度で設定されます。これを決定するには キャッシュエントリ乗数 テーブルを参照し、少なくともフラグメントと同じくらい大きな、最大サイズの最も小さい値を検索します。それは選択された big の値であり、従っておおよそのサイズの粒度を示すでしょう。それはフラグメントがディスクから読み込まれる際に発生しうる最大の余分なディスク I/O の量を表します。
ボリュームのインデックスエントリのセットは セグメント へグループ化されます。インデックスのセグメントの数は、 2^16 エントリを超えるセグメント数にならないように可能な限り少ないセグメントになるよう選択されます。内部セグメントの参照はそのため、セグメントの任意の他のエントリを参照する為に 16 ビット値を使用します。
セグメントのインデックスエントリは DIR_DEPTH (現在は 4)エントリ毎に バケット へグループ化されます。これらはセグメント毎に 2^14 未満のバケットを割り当てる標準的なハッシュテーブルの手法で処理されます。
| [2] | records.config のドキュメントの以前の版のコメントでこの値が 2 の冪乗でなければならないと述べていましたが、それは間違いだったため修正されました。 |
ディレクトリ検索¶
Directory probing is the locating of a specific directory entry in the
stripe directory based on a cache ID. This is handled primarily by the
function dir_probe(). This is passed the cache ID (key), a
stripe (d), and a last collision (last_collision). The last of
these is an in and out parameter, updated as useful during the probe.
Given an ID, the top half (64 bits) is used as a segment
index, taken modulo the number of segments in the directory. The bottom half is
used as a bucket index, taken modulo the number of buckets
per segment. The last_collision value is used to mark the last matching
entry returned by dir_probe.
適切なバケットを算出した後、バケットのエントリはマッチするものを探すために検索されます。この場合、マッチするかが キャッシュ ID ( キャッシュタグ ) の下位 12 ビットの比較によって検出されます。検索はバケットのベースエントリから開始して、その後先頭のエントリからのエントリ連結リストを使って進んでいkます。タグのマッチが発見されていてかつ collision が無い場合、エントリは返されて last_collision はそのエントリを指すように更新されます。 collision がセットされていて現在のマッチではない場合、検索は連結リストの次へ続きます。そうで無い場合 (訳注: collision がセットされていて現在のマッチである場合) collision をクリアし、検索を継続します。
これにより最後に返されたマッチしたもの (last_collision) が見つかるまでマッチングがスキップされ、その後に次のマッチするものが (もしあるなら) 返されます。検索が連結リストの最後まで到達した場合、失敗した結果が返される (もし最後の衝突がないなら)、あるいは衝突したエントリがバケットから削除されているとの想定の上で、衝突を解消した後に検索が再開されます。この処理は値が返されるまで繰り返すことができますが、正常なエントリがスキップされることがないことを保証します。
したがって最後の衝突は後で検索を再開するのに使用できます。返されたマッチしたものが実際のオブジェクトではないかも知れないため、これは重要です。 バケット への キャッシュ ID のハッシュ化とタグマッチングが偽陽性を発生しそうに無くても、それは使用可能です。フラグメントが読み込まれる際、キャッシュ ID の全てが使用可能でありチェックされた結果誤りがある場合、その読込みは破棄が可能でありキャッシュ仮想接続は最後の衝突値を追跡するためディレクトリから次のマッチする可能性があるものが検索されます。
キャッシュ操作¶
キャッシュアクティビティは HTTP リクエストヘッダがパースされ、リマップされてから開始します。トンネルされたトランザクションはヘッダがパースされることがないためキャッシュに影響しません。
ロジックを理解するため、 キャッシュバリッド という用語を紹介しなければなりません。これはキャッシュされるのに有効なオブジェクトに直接関係するものを意味します。 (例えばキャッシュバリッドな URL を参照する DELETE はそれ自身はキャッシュできません) Traffic Server はトランザクション中に何度かキャッシュの正当性を計算してキャッシュバリッドの結果によってのみキャッシュ操作を行うため、この用語は重要です。正当性の基準は同様にトランザクション中の変更を使用しました。この処理はキャッシュできないオブジェクトの為のキャッシュアクティビティによるコストを避けるために実行されます。
3 つの基本的なキャッシュ操作は検索、読込み、そして書込みです。エントリの削除はボリュームディレクトリが更新されるだけという書込みの特殊なケースとして扱います。
クライアントリクエストヘッダがパースされてキャッシュできると決定された後、 キャッシュ検索 が行われます。成功した場合 キャッシュ読込み が試みられます。検索か読込みのいずれかが失敗してかつコンテンツがキャッシュできると判断される場合、 キャッシュ書込み が試みられます。
キャッシャビリティ¶
キャッシュに関するリクエストで最初に行われるのは、キャッシュするのに潜在的に有効なオブジェクトであるかどうかを決定することです。最初のパースとリマップの後、このチェックは主にネガティブな結果を検出するために行われます。これはもしネガティブな結果が出た場合は全ての後のキャッシュ処理がスキップされる、すなわちキャッシュに配置されずキャッシュ検索も実行されなくなるためです。それらを変更する設定オプションに加え、必要条件が数多く存在します。追加のキャッシャビリティチェックは、トランザクションについてより多くのことが分かった際の処理 (プラグイン操作やオリジンサーバレスポンスのような) 以降に実行されます。それらのチェックについては関連する操作のセクションで適切に説明します。
キャッシャビリティに影響できる項目のセットは:
- 組込みの制約。
records.configの設定。cache.configの設定。- プラグインの操作。
初期の内部チェック、それらの records.config を伴った オーバーライド[#cacheability-overrides]_ は HttpTransact::is_request_cache_lookupable 内で処理されます。
実行されるチェックは以下の通りです。
- キャッシュ可能なメソッド
リクエストは
GET,HEAD,POST,DELETE,PUTのいずれかでなければなりません。See
HttpTransact::is_method_cache_lookupable.- 動的 URL
URL が動的であるため Traffic Server は動的コンテンツのキャッシングを避けようとします。もし以下の条件に当てはまるなら URL は動的であると考えられます。
HTTPやHTTPSではない- クエリパラメータを含む
aspで終わる- パスに
cgiを含むこのチェックは
proxy.config.http.cache.cache_urls_that_look_dynamicにゼロでない値を設定することで無効にできます。加えて、
cache.configにマッチするルールに TTL が設定されていたらこのチェックは行われません。- レンジリクエスト
records.configのproxy.config.http.cache.range.lookupがゼロでない値である場合に限りキャッシュバリッドです。これはレンジリクエストがキャッシュ可能であることを意味しません。キャッシュから満たされるかもしれないというだけです。加えて、proxy.config.http.cache.range.writeをレンジリクエストでキャッシュ書込みを強制を試みるように設定することが出来ます。これは今はあまり価値が無いかもしれませんが、例えばオリジンサーバーがRange:ヘッダーを無視するなら、このオプションはレスポンスをキャッシュすることを許すことが出来ます。ベストのパフォーマンスのため、デフォルトではproxy.config.http.cache.range.writeは無効になっています。
プラグインはリクエストがキャッシュバリッドと見なされる事を強制するため TSHttpTxnReqCacheableSet() を呼び出せます。
| [3] | コード上ではこのロジックにおいてステートマシンインスタンスの cache_info.directives の中の does_config_permit_lookup の値を設定することにより cache.config をチェックするように見えますが、その値が使用されている箇所は発見できません。 does_config_permit_storing ディレクティブが設定されてその後にチェックされるので、このディレクティブは(管理者の観点から)オブジェクトのキャッシュすることを妨げるのに効果的です。 |
キャッシュ検索¶
最初のリクエストがキャッシュ無効と判定されなければルックアップが実行されます。キャッシュルックアップはオブジェクトがキャッシュ内にあるか、キャッシュ内にある場合はどこに位置するかを判定します。時には、ルックアップは続けてディスクから最初の Doc を読み、オブジェクトがまだキャッシュに存在するかを確認します。
キャッシュルックアップの基本的なステップは :
キャッシュキーが計算されます。
これは通常はリクエストの URL を用いて計算されますが、 <cache-key> プラグインによって オーバーライド出来ます。キャッシュのインデックス文字列は保存されません。それはクライアントのリクエストヘッダーから計算可能という前提だからです。
キャッシュストライプが (キャッシュキーに基いて) 判定されます。
キャッシュキー は
Volインスタンスの配列へのキャッシュキーとして使用されます。この配列の生成と整列はボリュームがどのように割り当てられるかの本質です。キャッシュキーから計算されたインデックスキーを用いてキャッシュストライプディレクトリーが 調べられます 。
集約バッファー などさまざまな他の索引ディレクトリもチェックされます。
ディレクトリエントリが見つかったら最初の
Docがディスクから読まれ有効性が検証されます。This is done in
CacheVC::openReadStartHead()orCacheVC::openReadStartEarliest()which are tightly coupled methods.
If the lookup succeeds, then a more detailed directory entry (struct
OpenDir) is created. Note that the directory probe includes a check
for an already extant OpenDir which, if found, is returned without
additional work.
キャッシュ読込み¶
キャッシュ読込みは キャッシュ検索 が成功した後に開始されます。この時点で最初の Doc がメモリに読み込まれ、追加情報が参照可能になります。これはオブジェクトの全ての 代替 の HTTP ヘッダーを常に含みます。
この時点でオブジェクトの代替が選択されます。これはクライアントのリクエストを保存されたレスポンスヘッダーと比較することで実行されますが、 TS_HTTP_ALT_SELECT_HOOK を用いたプラグインで制御することも出来ます。
この時点でコンテンツはオブジェクトの 新鮮さ を計算することで 新鮮でない かどうかをチェックすることが可能になります。これは基本的にはヘッダーと場合によって他のメタデータを見ることによりオブジェクトがどれぐらい古いかをチェックすることになります (ヘッダーは代替を選択する前にはチェックできないことに注意してください) 。
この作業のほとんどは HttpTransact::what_is_document_freshness 内で行われます。
まず、 TTL (time to live) の値、これは cache.config で設定可能です、を見てリクエストが設定ファイルの行にマッチするかチェックされます。これはヘッダー内の日付ではなくオブジェクトがいつキャッシュに収納されたかに基いて行われます。
次に、内部フラグ (needs-revalidate-once) を見て cache.config の revalidate-after の値がセットされていないかをチェックします。セットされていればオブジェクトは 新鮮でない と印を付けられます。
これらのチェックの後オブジェクトの経過時間が HttpTransactHeaders::calculate_document_age で計算されます。その後設定された曖昧さ (fuzzing) が適用されます。利用可能なデータに基づくこの経過時間の限界は HttpTransact::calculate_document_freshness_limit によって計算されます。
この経過時間がどのように利用されるかは records.config の proxy.config.http.cache.when_to_revalidate によって決定されます。これが 0 なら組み立てられた計算を使って新鮮さの限界とドキュメントの経過時間を比較します。ドキュメントの経過時間は cache.config で明示的に上書きされない限りクライアントが提供したキャッシュ制御の値 (max-age, min-fresh, max-stale) のいずれかで調整されます。
オブジェクトが新鮮であればクリアントに配信されます。新鮮でなければクライアントのリクエストは 再確認 のために If Modified Since に変更されるかもしれません。
リクエストは CacheVC を生産者 (producer) としクライアントの NetVC をシンク (sink) とする標準の仮想接続トンネル (HttpTunnel) を用いて処理されます。もしリクエストがレンジリクエストであれば、これはオブジェクトの適切な部分を選択するために変換で調整されるか、リクエストが単一のレンジを含む場合はレンジ加速を使用可能です。
レンジ加速は全てのフラグメントのオフセットを含む最古の Doc に添付されたフラグメントオフセットテーブルが最初のレンジを過ぎたかを調べることによって行われます。これにより中間のフラグメントの読込みを実行するのではなくリクエストされた最初のバイトを含むフラグメントを直ちにロードすることを可能にします。
キャッシュ書込み¶
キャッシュへの書込みは CacheVC クラスのインスタンスによって処理されます。これはデータを受信しシンクとして振る舞うキャッシュに書き込む仮想接続です。標準トランザクションに対する仮想接続 (VConns) 間のデータ転送は HttpTunnel によって処理されます。キャッシュへの書込みは CacheVC のインスタンスをトンネル消費者として取り付けることによって行われます。そのためデータをクライントへ転送する仮想接続と並列に実行されます。データはキャッシュに流れてそれからクライアントに流れるのではなく、分割されて両方の向きに同時に流れます。これにより 2 つの間のデータ排他制御の問題を回避しています。
それぞれの CacheVC はトランザクションを独立に処理しますが、 volume のレベルで相互作用します。それぞれの CacheVC はデータをボリュームコンテンツに書き込むようにボリュームオブジェクトを呼び出すからです。 CacheVC はトランザクションが完了するかデータ量がターゲットフラグメントサイズを超えて書き込むまではデータを内部に蓄積します。前者の場合はオブジェクト全体がボリュームに提供され書き込まれます。後者の場合はターゲットフラグメントサイズのデータが提供され CacheVC は後続のデータを処理し続けます。今度はボリュームがこれらの書込みリクエストを 集約バッファー と呼ばれる保留領域に配置します。
ターゲットフラグメントサイズ以下のオブジェクトについては順序の考慮はなく、オブジェクトはボリュームコンテンツに単に書き込まれます。より大きなオブジェクトについては最古の Doc が最初に書き込まれ最初の Doc が最後に書き込まれます。これがオブジェクトが上書きされるべきかを判定するためのちょっとした能力を提供します。書込みカーソルの性質により (最古の Doc 内の)、最初のフラグメントが上書きされることなしに最初のフラグメントの後のフラグメントが上書きされることはありません (オブジェクトがキャッシュに書き込み済みになった時点で書込みカーソルは最初の Doc に位置していることを私達は知っているからです) 。
注釈
ターゲットフラグメントサイズを超えたデータを提供しないことは CacheVC の責任です。
更新¶
キャッシュ書込みはキャッシュ内の既存のオブジェクトが修正されるケースもカバーします。これは以下の場合に発生します :
- 条件付きリクエストがオリジンサーバーに送られて
304 - Not Modifiedレスポンスを受信した。 - オブジェクトの代替が オリジンサーバー から取得されてオブジェクトに追加された。
- (例えば
DELETEリクエストのために) オブジェクトの代替が削除された。
どんな場合にもオブジェクトのメタデータは修正されなければなりません。 Traffic Server は既にキャッシュ内にあるデータは決して更新しないのでこれは最初の Doc がキャッシュに再度書き込まれるとボリュームディレクトリエントリが更新されることを意味します。クライアントリクエストは既に処理されているので最初の Doc はキャッシュから読まれてメモリ城にあります。代替ベクターは適切に (エントリが追加、削除、あるいは新しい HTTP ヘッダを含むように変更される) 更新され、その後ディスクに書き込まれます。複数の代替が異なる CacheVC インスタンスにより同時に更新されます。唯一の制約は最初の Doc です。それぞれの代替の残りのデータは完全に独立です。
集約バッファー¶
キャッシュへのディスク書込みは 集約バッファー を通して処理されます。 Vol インスタンスのそれぞれに対して 1 つ存在します。システムコールの回数を最小化するためデータはディスクにおよそ ターゲットフラグメントサイズ バイトの単位で書き込まれます。使用されるアルゴリズムは単純です。データはこれ以上追加するとターゲットフラグメントサイズを超えてしまうようになるまで集約バッファーに集積され、その時点でバッファーはディスクに書き込まれ、バッファ内のデータとオブジェクトに対するボリュームディレクトリエントリがそれらのオブジェクトの実際のディスク上の位置 (それらはディスクに書き込む行為によって決定されます) で更新されます。バッファーが書き出された後にそれはクリアーされて上記の手順が繰り返されます。集約バッファーのための特別なルックアップテーブルがあり、オブジェクトのルックアップはキャッシュデータをそのメモリ上で見つけることが出来ます。
集約バッファー内のデータはキャッシュの他の部分、特に キャッシュルックアップ にも見えるので、部分的に満たされた集約バッファーをディスクに書き出す必要はありません。実際に、そういったデータはバッファーを満たす追加のキャッシュコンテンツが届くまでメモリ上にキャッシュされています。
フラグメントサイズはディスク書込みの操作を分配することにしか使われないため、ターゲットフラグメントサイズは小さなオブジェクトにはあまり影響を及ぼしません。より大きなオブジェクトに対してはそれらのオブジェクトをフラグメントに分割してボリューム内の異なる位置に配置することになるので非常に大きな影響を及ぼします。各フラグメントの書出しはボリューム内の自身のエントリを持っていて、それらは計算によって繋がれています (各 キャッシュキー は 1 つ前の値から計算されます)。もし可能なら、フラグメントテーブルは最古の Doc 内に蓄積されます。最古の Doc は各フラグメントの最初のバイトのオフセットを持っています。
退避メカニズム¶
デフォルトでは書込みカーソルは キャッシュストライプ を少なくとも 1 度周回したら進むに連れてオブジェクトを上書き (キャッシュからの事実上の追い出し) します。ある場合にはこれは受け入れることが出来ずオブジェクトはキャッシュから読み込まれてキャッシュに書き戻され、オブジェクトの物理ストレージを書込みカーソルの前から書込みカーソルの後ろに移動することで 退避 されます。退避されたオブジェクトは (Vol インスタンスに付与された) ストライプデータ構造内のデータに基いてこのように扱われます。
Evacuation data structures are defined by dividing up the volume content into
a disjoint and contiguous set of regions of EVACUATION_BUCKET_SIZE bytes.
The Vol::evacuate member is an array with an element for each
evacuation region. Each element is a doubly linked list of EvacuationBlock
instances. Each instance contains a Dir that specifies the fragment
to evacuate. It is assumed that an evacuation block is placed in the evacuation
bucket (array element) that corresponds to the evacuation region in which the
fragment is located although no ordering per bucket is enforced in the linked
list (this sorting is handled during evacuation). Objects are evacuated by
specifying the first or earliest fragment in the evactuation block. The
evactuation operation will then continue the evacuation for subsequent fragments
in the object by adding those fragments in evacuation blocks. Note that the
actual evacuation of those fragments is delayed until the write cursor reaches
the fragments, it is not necessarily done at the time the earliest fragment is
evacuated.
2 つの種類の退避があります。 リーダー (reader) に基づく と 強制される です。 EvacuationBlock はこれを追跡するためにリーダーの数を持っています。リーダーの数がゼロなら、それは強制された退避であり、ターゲット、もしそれが存在するなら、は書込みカーソルが近くなったときに退避されるでしょう。リーダーの数がゼロでない場合はそれはオブジェクトを読みだすことができると現在期待されているエンティティの数です。リーダーはオブジェクトへの読み取りアクセスを要求されたときにカウントを増加させるか、 1 のカウントとともに EvacuationBlock を作成します。リーダーがオブジェクトを読み終えた時はカウントを減少させカウントがゼロになったら EvacuationBlock を削除します。もし EvacuationBlock がカウントがゼロで既に存在していたら、カウントは変更されず、リーダーの数も追跡されません。そのためオブジェクトが存在する限り退避は有効になります。
Evacuation is driven by cache writes, essentially in Vol::aggWrite.
This method processes the pending cache virtual connections that are trying to
write to the stripe. Some of these may be evacuation virtual connections. If so
then the completion callback for that virtual connection is called as the data
is put in to the aggregation buffer.
When no more cache virtual connections can be processed (due to an empty queue
or the aggregation buffer filling) then Vol::evac_range is called
to clear the range to be overwritten plus an additional EVACUATION_SIZE
range. The buckets covering that range are checked. If there are any items in
the buckets a new cache virtual connection (a doc evacuator) is created and
used to read the evacuation item closest to the write cursor (i.e. with the
smallest offset in the stripe) instead of the aggregation write proceeding. When
the read completes it is checked for validity and if valid, the cache virtual
connection for it is placed at the front of the write queue for the stripe and
the write aggregation resumed.
Before doing a write, the method Vol::evac_range() is called to
start an evacuation. If any fragments are found in the buckets in the range the
earliest such fragment (smallest offset, closest to the write cursor) is
selected and read from disk and the aggregation buffer write is suspended. The
read is done via a cache virtual connection which also effectively serves as the
read buffer. Once the read is complete, that cache virtual connection instance
(the doc evacuator) is placed at the front of the stripe write queue and
written out in turn. Because the fragment data is now in memory it is acceptable
to overwrite the disk image.
通常のストライプへの書込みが再開した時は同じチェックが再び実行され、 (もし必要なら) フラグメントの退避と続いて書込みへのキューイングが行われることに注意してください。
ディレクトリへの更新は対比したフラグメントの書込みが完了したときに行われます。複数のフラグメントからなるオブジェクトはフラグメントの読込みが完了したときに検出されます。もしそれが最初のセグメントでなかったら次のフラグメントに退避の印が付けられます (そして次にそれが読み込まれたら後続のフラグメントが引っ張られます。ロジックは 代替 の終了が次のキーがディレクトリ内に無いときだという前提です。
これは集約書込みロジックの 1 度に 1 つずつ の戦略と相互作用します。フラグメントが対比されようとしているフラグメントに近い場合は、それは結局同じ退避バケット内になるかもしれません。集約書込みは退避する次のフラグメントを毎回チェックするので、次のフラグメントを見つけてそれが上書きされる前に退避するでしょう。
退避処理¶
退避されるフラグメントの主な発生源はアクティブフラグメントです。つまり、読込みもしくは書込みのために現在オープンされているフラグメントです。これは上記の退避ブロック内のリーダーの数によって追跡されています。
オブジェクトのピン留めが有効なら、書込みカーソルが移動してピン留めされたオブジェクトを検出したときに定期的にスキャンが実行されそれらに退避の印を付けます。
フラグメントは ヒット退避 を通して退避することも出来ます。これは proxy.config.cache.hit_evacuate_percent と proxy.config.cache.hit_evacuate_size_limit で設定されます。フラグメントが読み出された時それが書き込みカーソルに近くて手前にあるかチェックされます。近いというのはストライプのサイズの指定したパーセントより小さいかどうかです。もしデフォルト値の 10 に設定されていたらフラグメントがストライプのサイズの 10% 以内にあれば、退避の印を付けられます。この印はフラグメントがオープンされている間に書込みカーソルがフラグメントを通過したら (全てのオープンされたオブジェクトが退避されたら) クリアーされます。オブジェクトがクローズされたときにフラグメントにまだ印がついていたら適切な退避バケットに配置されます。
初期設定¶
Initialization starts with an instance of Store reading the storage
configuration file, by default storage.config. For each valid element in
the file an instance of Span is created. These are of basically
four types:
- ファイル
- ディレクトリ
- ディスク
- ローデバイス
After creating all the Span instances, they are grouped by device
ID to internal linked lists attached to the Store::disk
array[#store-disk-array]_. Spans that refer to the same directory, disk, or raw
device are coalesced in to a single span. Spans that refer to the same file
with overlapping offsets are also coalesced [5]. This is all done in
ink_cache_init() called during startup.
注釈
スパンロジックは HostDB でも使われていて、 1 つより多い他の説明し難い機能がそのモジュールのスパンロジックにより提供されています。
After configuration initialization, the cache processor is started by calling
CacheProcessor::start. This does a number of things:
For each valid span, an instance of CacheDisk is created. This
class is a continuation and so can be used to perform potentially
blocking operations on the span. The primary use of these is to be passed to
the AIO threads as the callback when an I/O operation completes. These are then
dispatched to AIO threads to perform storage unit initialization. After
all of those have completed, the resulting storage is distributed across the
volumes in cplist_reconfigure. The
CacheVol instances are created at this time.
Cache stripe assignment setup is done once all stripes
have initialized (that is, the stripe header information has been successfully
read from disk for all stripes). The assignment information is stored as an
array of indices. These are indices in to an array of stripes. Both the
assignment and the stripe arrays are stored in an instance of CacheHostRecord.
Assignment initialization consists of populating the assignment array, which is
much larger than the stripe array.
There is an instance of CacheHostRecord for each line in
hosting.config and one generic record. For the configured instances, the
set of stripes is determined from the cache volume specified in the line. If no
lines are specified, all stripes are placed in the generic record, otherwise
only those stripes marked as default are placed in the generic record.
注釈
格納するレコードが指定された場合、最低 1 つのデフォルトキャッシュボリュームを指定しなければエラーとなります。
The assignment table is initialized in build_vol_hash_table which is
called for each CacheHostRecord instance. For each stripe in the
host record, a sequence of pseudo-random numbers is generated. This begins with
the folded hash of the stripe hash identifier, which is the device path followed
by the skip and size values for that stripe, making it unique. This
also makes the sequence deterministic for any particular stripe.
それぞれのストライプはそのシーケンス内でストレージの VOL_HASH_ALLOC_SIZE (現状 8MB)ごとに 1 つの数字を得ます。これらの数字はストライプのインデックスとペアにされ、全てのストライプを横断して結合され、そしてランダムな値によってソートされます。結果として作られる配列はストライプ割り当てテーブル内の各スロットでサンプリングされます。サンプリングは最大のランダムな値を割り当てテーブルのサイズで割って、割った結果の各倍数の間の中間の値を使って行われます。次に合体された擬似乱数のシーケンスから各サンプルがスキャンされサンプルより大きくない最初の数字が見つかります。その値に関連付けられたストライプがその割り当てテーブルのエントリとして使用されます。
この手続は決定性を持っていますが、各ストライプのサイズを含む初期状態に影響を受けやすいです。
脚注
| [4] | メモリキャッシュ内にあるオブジェクトを含むように拡張する作業 <https://issues.apache.org/jira/browse/TS-2020>`_ が進行中です。 |
| [5] | この連結リストは後の処理ではほとんど無視されます。それは同じデバイス上の 1 つを除いた全てののファイルやディレクトリのストレージユニットが無視されることを引き起こします。 TS-1869 を参照してください。 |